In the fall of 2025, I was up one morning doing my typical reading of recent papers in the retrieval/long context/document processing space and the LAD-RAG paper came across my browser. The paper is titled LAD-RAG: Layout-aware Dynamic RAG for Visually-Rich Document Understanding. Whoa. That title’s hitting a lot of keywords in my brain.
I had been tracking the “OCR 2.0” space for quite some time, and the second half of 2025 brought about an explosion of tiny, fine-tuned, layout-aware document extraction models that appeared to have great results. I was especially excited by these models since up to that point, the RAG pipelines I had worked on had either employed vanilla, chunked-text-based RAG or page-image based RAG.
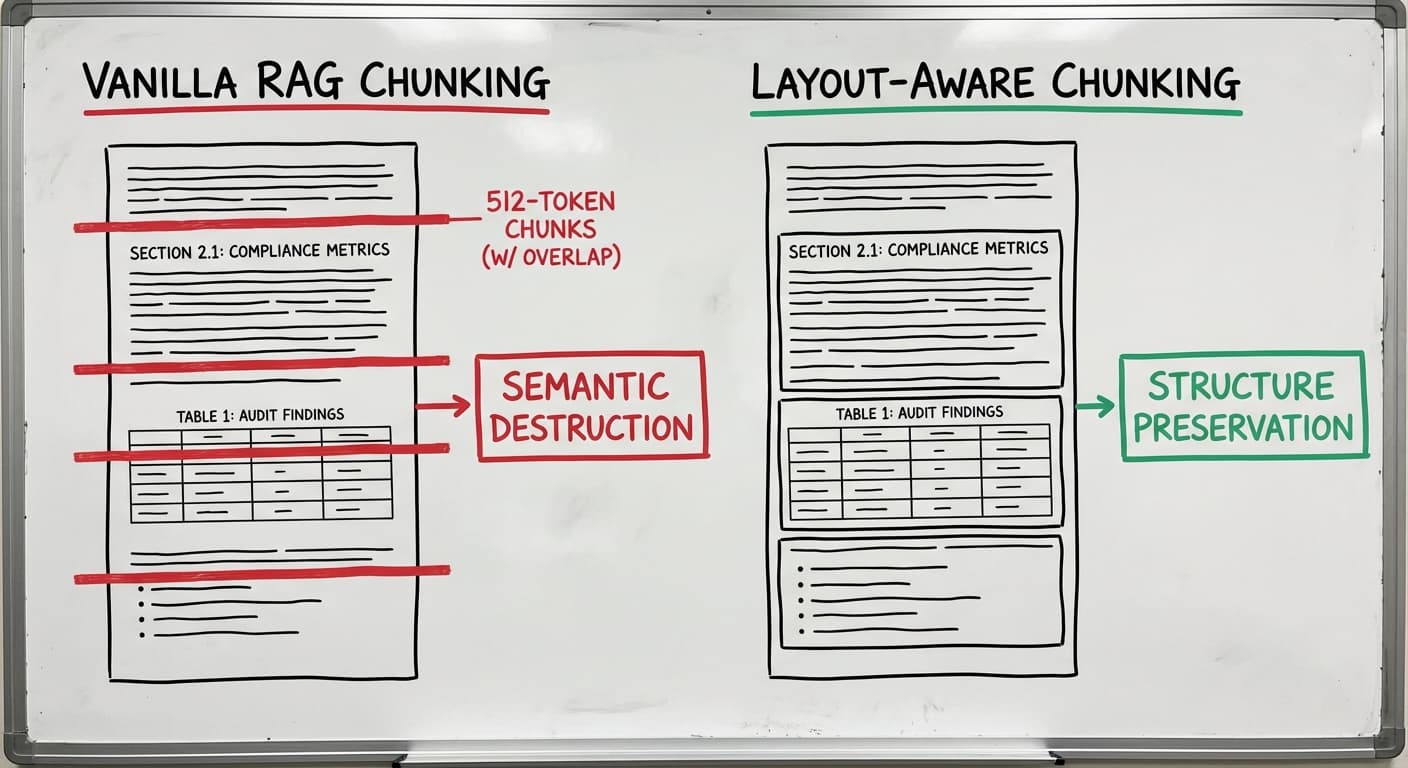
The former destroyed the deep semantic information contained in layout and the latter polluted the context window and exploded vector search storage economics. They both failed quickly with any sort of multi-hop or very targeted question which were often some of the first questions a user would try. These tiny layout-aware models promised staying in the text modality, preserving the profoundly important layout of the text and did not consume foundation model quota.
However, even after introducing a layout-aware document extraction model, any RAG system (at least in the fall of 2025) was still faced with the ever-present question of “how do I chunk this text?”
The moment any well-known chunking method was introduced, some semantic information was lost. It always felt like any RAG system should attempt to “chunk” text the same way humans do: using document layout like headers, lists, paragraphs etc. The human-chunking technique maintained semantic information between layout-based chunks: for example, a header might define a new section of paragraphs, all grouped underneath that header. A RAG system should be able to recognize this and each paragraph should maintain its grouping under that header.
This sounds simple enough, but humans also employ another chunking technique because of physical limitations: pages. Pages (typically) do not chunk concepts into nice packages like layout does, they simply exist so a human can hold a book and turn a page.
Humans turn pages and can connect what they’re currently reading back to concepts discussed on previous pages. However, our RAG systems up to this point struggled with this sort of thing. We didn’t want to deal with pages, so we converted our documents into giant amorphous blobs of text and created coarse, arbitrary cut points in the blob to satisfy our context window masters.
LAD-RAG quickly piqued my interest because it seemed to address many of these issues. The authors split up documents by pages and extracted layout-aware nodes out of each page. LAD-RAG would then (in the document processing step), page by page, extract the section hierarchy out of the document, extract a set of working memory (entities, semantic topics, unresolved objects) and finally build a graph of cross-page connections from the current page’s nodes back to nodes on previous pages. This meant that the document was chunked the way the author intended, by its layout, and the page problem was addressed by creating a graph of semantic edges to represent cross-page connections.
LAD-RAG then tickled another itch that had been growing in my brain: once the document is processed, instead of deterministically retrieving some context to answer a question, LAD-RAG let the LLM decide how and what it wants to retrieve while it builds a set of evidence to answer a question.
I had recently read this blog post: The RAG Obituary, in which where the author argued that retrieving (or investigating) over long documents was better suited to a Claude Code approach: provide the raw document data in a file system and just give an agent some foundational tools to interact with that raw document data. The industry would sum this up as “Agentic Search over Documents.”
Having spent the past four years wrestling with mostly vanilla-RAG systems running over 300+ page compliance documents, these ideas definitely made me wonder if agentic search was the next step. Luckily, LAD-RAG’s approach to inference was exactly this: process the document into this graph structure, then provide an “agent” a set of tools to retrieve/explore that graph system and let it decide how it wants to proceed. So LAD-RAG was ticking a lot of boxes:
- Use the chunking mechanism the author intended via layout
- Maintain semantic connections across pages
- Provide this data via a set of tools to an agent to answer questions
At this point, any AI engineers worth their salt are screaming at their monitor: “how are you possibly going to run all of those LLM requests at scale??” The moment you have a handful of 300+ compliance documents uploaded concurrently into your system you either instantly exhaust your quota or tell your user to go take a nap waiting for their documents to finish processing. A couple other things happened in the fall of 2025 that quieted this screaming in my head. Silenzio Bruno.
Drata had recently prioritized improvements to core retrieval systems, specifically regarding how we process Vendor Risk Management (VRM) documents. I saw this as an opportunity to compile the trove of information I’d jammed into my brain around recent innovations in the retrieval-over-long documents space. Ironically, in the architecture document I produced, I did not propose LAD-RAG, but rather, I mentioned it in the conclusion as a future direction we might go in. However, a large part of the architecture I produced was powered by small, open models running on Cloud Run Functions with attached GPU. The argument here was simple:
- Small, open models have gotten surprisingly good (Qwen3/Qwen3-VL had just been released).
- Cloud Run enables pay-as-you-go usage on 24GB of VRAM.
- This means we can run these small models with great economics (no constantly running, unused, GPUs).
- Therefore, save your foundation model quota for inference and perform your document processing on ephemeral GPUs.
It’s easy to overlook just how amazing the Cloud Run offering is. Ephemeral compute with a decent-sized attached GPU. In my opinion, this changes how we can think about offline processing for RAG. Now we can care less about the number of LLM calls we’re making; instead we should be thinking about how to increase the number of LLM calls (especially calls we can make in parallel) so that the tasks become simpler. You might think this approach increases your exposure to hallucinations, but there is some precedent that reducing task complexity by increasing LLM calls reduces hallucinations.
There is no free lunch in life, however. Cloud Run functions with attached GPU come with a catch: their initial quotas are much lower than non-GPU counterparts and they employ instance based pricing. What this means is, when you kick off a cloud run function, it does its work then hangs around for ~15ish minutes staying warm in case other requests arrive. Normally, you pay only for the portion where the compute is occurring, not for the 15 minutes of hanging around. When a GPU is attached, you pay for the entire time the function is warm. So you’re still paying for unused GPU time (likely less than a single GPU), but wouldn’t it be nice if we could pay only when the GPU is being used.
As I was creating the architecture document, I came across Cloud Run Jobs. You invoke a job, it spins up n cloud run instances with n attached GPUs, performs its processing, then spins down the instances and GPUs. This contains your cost fully to when the GPUs are processing. So you pay a latency cost of cold starting, but your GPU costs will never expand wildly outside your expectations. Cloud run jobs with attached GPU open the door to LLM-request-heavy offline document processing which, in my opinion, has never been the case before. This is a big reason why I invested any time at all into exploring LAD-RAG.
I should mention that my exploration of LAD-RAG did not include the full soup-to-nuts implementation of how document processing would run in production on a small open model in a cloud run job.
The native implementation of LAD-RAG’s document processing system has LLM requests that depend on each other, so there is definitely some innovation that would need to occur here to heavily parallelize it (I did some initial documenting of a map-reduce-like approach, but no implementation/testing). But I don’t think there is a clear blocker here that rules it out. I hope to continue the exploration and create this approach to production in a follow on blog. To maintain my sanity during the experiment, I ran all LLM calls on Gemini 2.5 Flash and Flash Lite to know I wasn’t too far off from smaller, open weight models.
The Problem: Vanilla RAG on Long Documents
Before diving into LAD-RAG’s approach and what we learned implementing it, here are the problems I kept running into with traditional RAG systems. These aren’t theoretical concerns, they’re patterns I’ve watched fail repeatedly on real compliance documents.
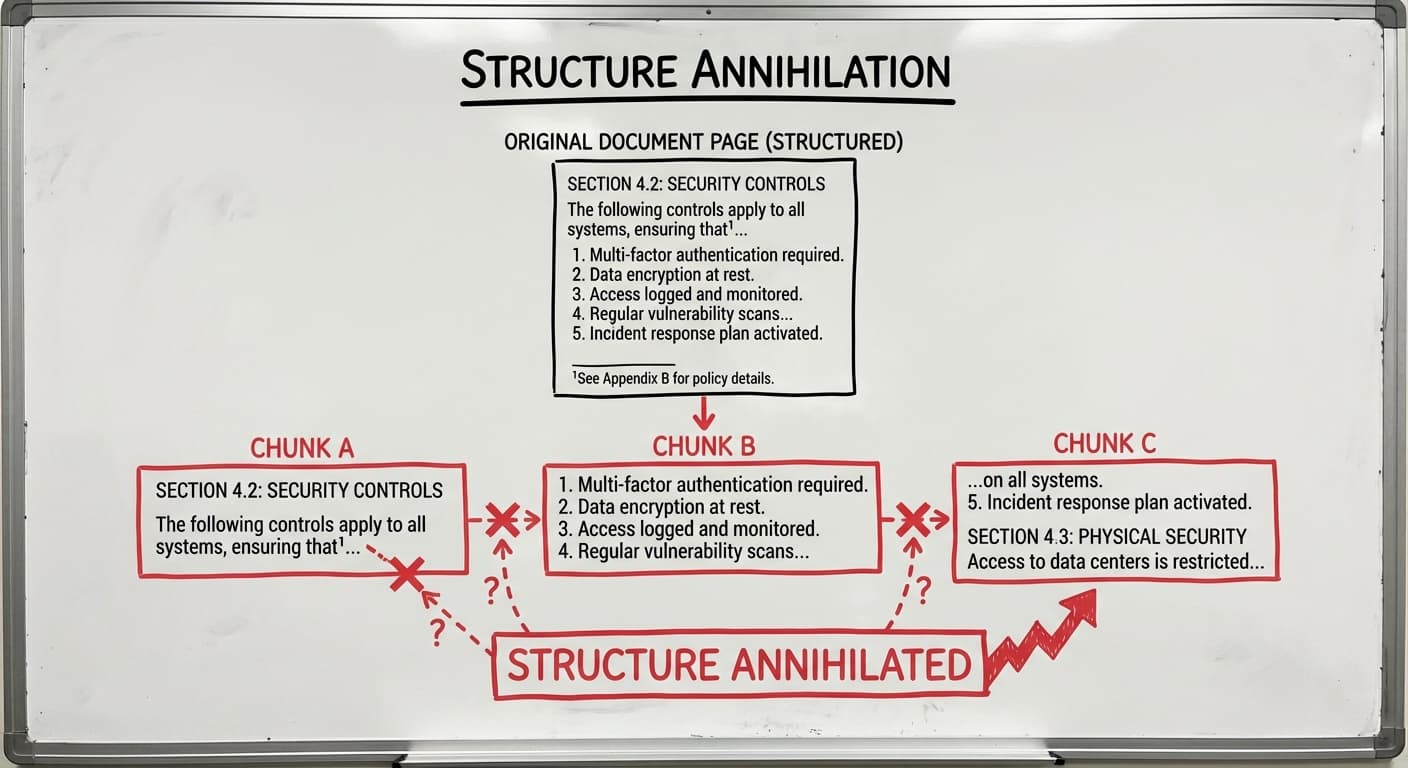
Structure Annihilation
When you chunk a 300 page SOC2 report into arbitrary windows with overlap, you systematically destroy structure. Consider what gets lost:
- A section header on page 23 that governs the interpretation of the next 15 paragraphs
- A table that spans pages 45–47 with footnotes explaining the column meanings
- A numbered list where item 3.1.4.2 only makes sense in the context of items 3.1.1 through 3.1.4.1
- Cross-references like “See Section IV.B.2 above” that become meaningless when Section IV.B.2 lands in a different chunk
Traditional chunking treats documents as unrelated snippets when they’re written to be read in order. Compliance documents, and most business documents, are structured arguments. The structure is a huge part of the meaning. When you lose the structure, you lose the document’s intent.
A vanilla RAG system can return a paragraph stating “The following controls apply:” with no controls. They were in the next chunk. The semantic connection was severed at an arbitrary token boundary.
Static Top-K Blindness
Traditional RAG systems retrieve the top-k most semantically similar chunks for every query, regardless of what kind of question is being asked. Fixed k can appear to work well in a majority of cases and then fail spectacularly.
First, different questions require radically different evidence volumes. “What is the org’s password policy?” might need 2–3 paragraphs. “How many controls address data encryption across this document?” might need content from 40 different pages. Using the same k=10 for both queries means you either over-retrieve for simple questions (wasting context window) or under-retrieve for complex questions (missing critical evidence).
Second, some questions aren’t about semantic similarity at all. “How many tables in this document reference SOC2 CC6.1?” is a structural query. The answer requires enumerating document elements by type and checking their content. Embedding similarity won’t find this.
A user might ask a perfectly reasonable question like “What controls are tested annually?” and get back a grab-bag of paragraphs that happened to contain the word “annual” but collectively failed to answer the question because the evidence was scattered across disconnected chunks.
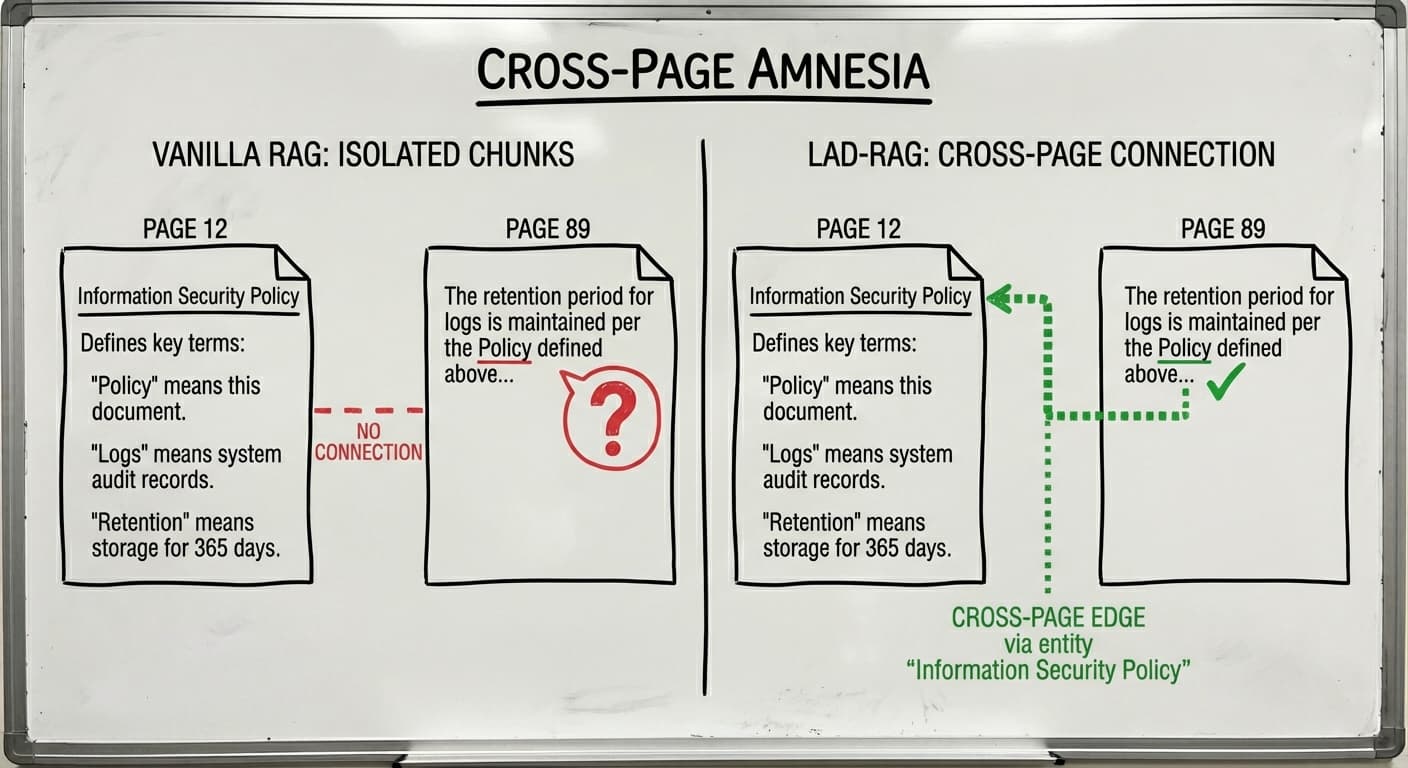
Cross-Page Amnesia
Vanilla RAG treats each chunk as an independent unit. There’s no mechanism to connect a definition introduced on page 5 with its application on page 67, unless they happen to share enough semantic overlap to land in the same retrieval batch.
Real documents don’t work this way. Compliance reports are full of forward references (“as described in Section 7”), backward references (“per the Password Policy defined above”), and thematic threads that weave through hundreds of pages. A skilled human reader maintains mental context as they progress through a document. They remember that “the Policy” on page 89 refers to the Information Security Policy introduced on page 12.
Vanilla RAG systems have no such memory. Chunks don’t know about each other.
A RAG system might confidently answer “What is the retention period for audit logs?” with “Logs are retained per the Data Retention Policy.” The actual retention period, 365 days, was defined in the Data Retention Policy on page 34. The system found a reference to the answer but couldn’t follow it to the answer itself.
The Compound Failure
These issues compound. Consider a question like: “How many password-related controls reference the Information Security Policy?”
To answer this correctly, you need to:
- Understand that “password-related controls” might appear under multiple section headers across the document (structure awareness)
- Enumerate all such controls, not just the top-k most similar (dynamic retrieval)
- For each control, trace any references back to the Information Security Policy defined elsewhere (cross-page connection)
Vanilla RAG fails at all three steps. Auditors ask questions like this daily.
This is the problem space I had a feeling LAD-RAG might address. Implementing it taught me that even the paper’s solutions needed significant hardening to work on long-context documents.
LAD-RAG: The Paper’s Approach
At a high level, LAD-RAG does two things: an ingestion phase that builds a rich document representation, and an inference phase where an LLM agent dynamically retrieves evidence. Retrieval over structured documents requires both semantic understanding and explicit structural reasoning; the system should decide which approach to use (or both) based on the question.
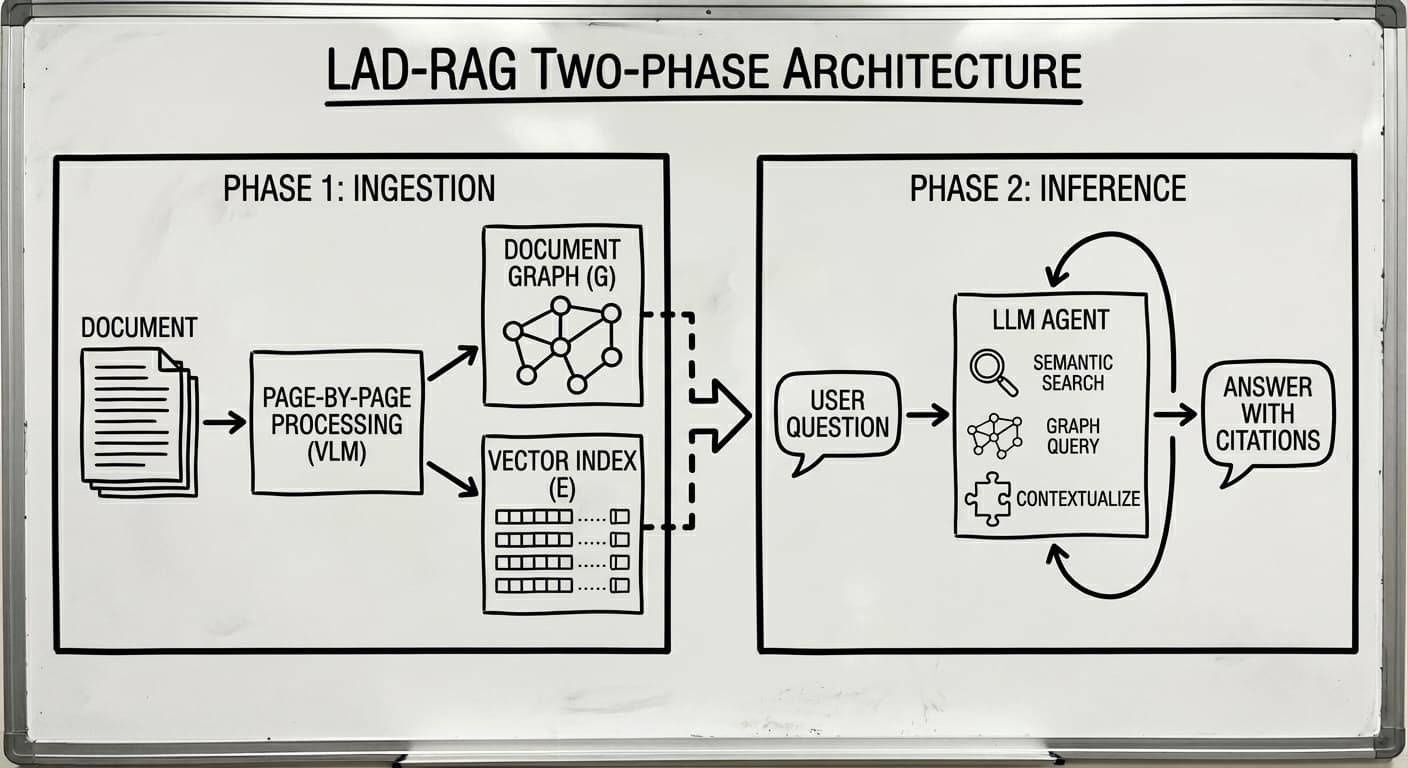
Building the Document Graph
During ingestion, LAD-RAG processes documents page by page using a foundation vision-language model. In a production setting, I’d reach for one of the small layout-aware models I mentioned above. For each page, the model extracts all visible elements: paragraphs, tables, figures, section headers, footnotes, and generates rich metadata for each:
- Layout position (top-left, center, footer section)
- Element type (paragraph, table, figure, section_header, etc.)
- Raw content (the actual text or description)
- Self-contained summary (a standalone description useful for retrieval)
- etc
These elements become nodes in a document graph. The interesting part is the edges.
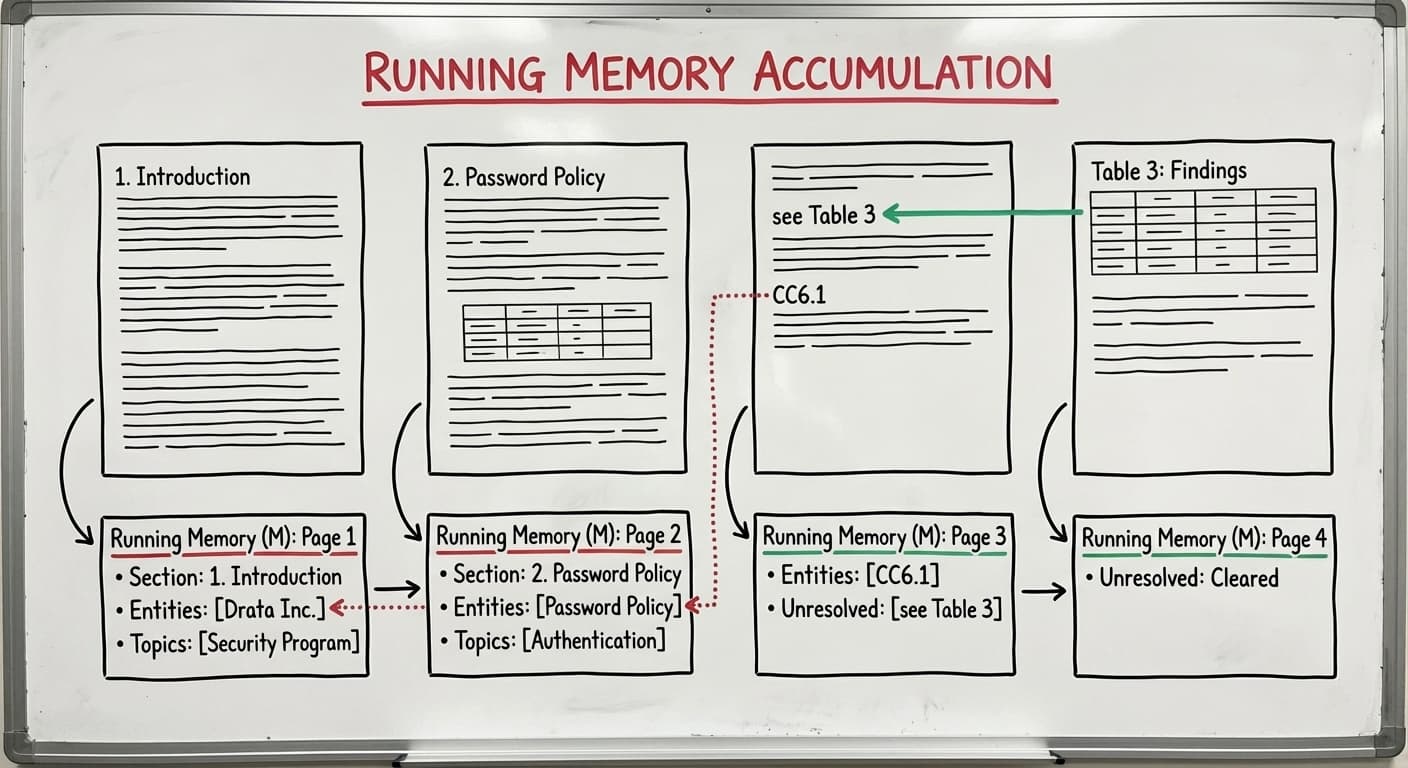
Running Memory: The Human Reader Simulation
The paper introduces a “running memory” (M) that tracks what a reader would remember while progressing through a document. This memory tracks:
- Section hierarchy: The current position in the document’s structure
- Active entities: Important references that persist across pages (e.g., “Password Policy”, “CC6.1”)
- Semantic topics: Core themes being discussed that span multiple pages
- Unresolved objects: Forward references like “see Table 3” that haven’t been explained yet
As each page is processed, the model connects new elements to this running memory, creating cross-page edges in the document graph. If page 15 references “the Password Policy defined above,” the system can create an explicit edge back to the Password Policy header on page 3.
The edges capture multiple relationship types:
- Hierarchical: A paragraph belongs to a section
- Reference: A footnote references a figure
- Semantic continuation: A paragraph continues the discussion from the previous page
- Updates: A list item updates a paragraph
- Summarizes: A node summarizes a topic or entity.
Neural-Symbolic Indexing
The output of ingestion is stored in two complementary forms:
- Symbolic graph index (G): The full document graph with structured properties and explicit relationships. This enables queries like “find all tables in section 3” or “get all elements connected to the Password Policy.”
- Neural index (E): Vector embeddings of the self-contained summaries of all nodes. This enables semantic similarity search: finding elements that are conceptually related to a query even if they don’t share exact terminology.
Without both, you miss either semantic matches or structural queries. Some questions are best answered through embedding similarity (“What is the company’s approach to data encryption?”). Others require structural reasoning (“How many figures in this report cite external sources?”). LAD-RAG maintains both pathways.
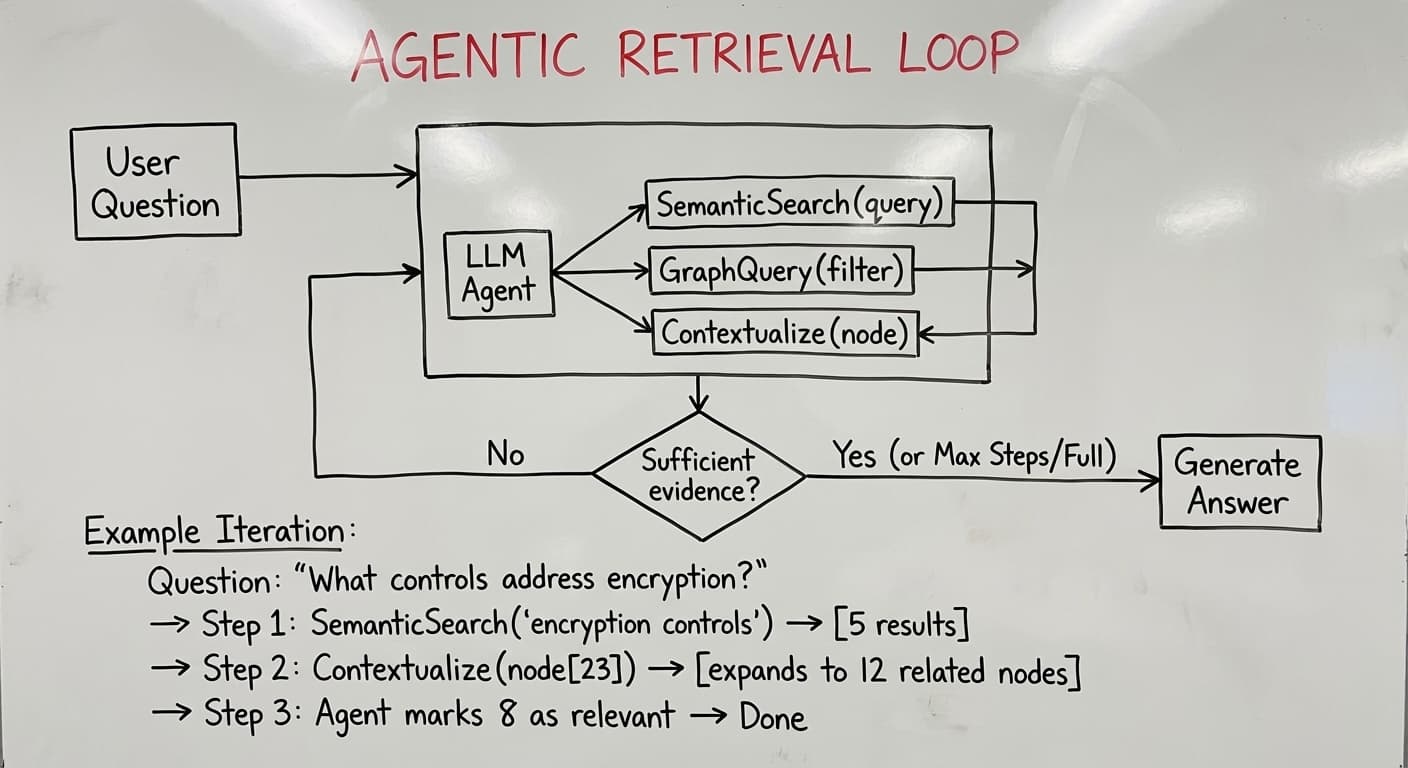
The Agent Loop
At inference time, instead of retrieving a fixed top-k chunks, LAD-RAG uses an LLM agent that searches iteratively across both indices. The agent has three tools:
NeuroSemanticSearch(query): Standard embedding similarity search. The agent can vector search the question.
SymbolicGraphQuery(query_statement): Structured queries over the document graph. The agent generates filter expressions to select nodes by type, section, page, or other properties. This is how you answer “find all tables” or “get everything in section 4.”
Contextualize(node): Given a node, expand to related content via graph structure. This uses Louvain community detection to find clusters of semantically related nodes, plus local neighborhood traversal. If you find one relevant paragraph, contextualization might surface the entire section it belongs to.
The agent iterates, searching, filtering, contextualizing, until it determines sufficient evidence has been gathered. Termination happens when a maximum number of steps is reached, or the agent decides it has enough evidence.
Performance Claims
The paper reports results across four benchmarks (MMLongBench-Doc, LongDocURL, DUDE, MP-DocVQA):
- 90%+ perfect recall on average without any top-k tuning
- Up to 20% improvement in recall at comparable noise levels vs. baseline retrievers
- Minimal latency: 2–5 LLM calls per query, 97% generating fewer than 100 tokens
To match LAD-RAG’s recall, traditional retrievers needed k=25–29 on the harder benchmarks. LAD-RAG achieved it dynamically, retrieving only what was necessary for each question.
What the Paper Leaves Unsaid
Reading the paper, I was excited but also cautious. Extracting memory items and building a graph sounded amazing, but how would it function when processing a document with 100s of pages? How does the memory behave on page 200? What happens when the graph gets dense? How do you prevent the extraction model from hallucinating relationships?
I’m not criticizing the paper, it’s an innovative, compelling approach. I read a lot of these types of papers and this was one of the few that inspired me to go build something because it felt like it could be the future. But the above questions I knew I’d need to answer if I wanted to use this approach on real 300-page compliance documents.
The ideas are interesting: layout-aware extraction, dual neural-symbolic indexing, and dynamic agentic retrieval. The question was whether they’d work on long, dense compliance documents that Drata’s customers rely on daily.
What’s Next: The Implementation Journey
In Part 2 of this series, I’ll walk through the implementation journey of building LAD-RAG++. The paper’s elegant ideas met reality when we started processing real 88-page SOC2 reports with dense tables and hundreds of cross-references.
You’ll see how:
- The naive implementation immediately hit scaling walls with memory explosion and token limits
- We developed edit-based memory, topic graduation, and deterministic linking to tame edge explosion
- LLM generation loops required multiple layers of degeneration prevention
- Graph density threatened to collapse Louvain communities into useless blobs
- The inference system needed innovations in contextualization, reranking, and evidence presentation
The journey from “this paper looks promising” to “this actually works on production documents” involved significant engineering. Part 2 documents every hard-won lesson.