
Every year, companies spend countless hours manually matching their custom security controls to standardized compliance requirements. At Drata, we built a RAG (Retrieval-Augmented Generation) application that automates this process down to just a few minutes, all powered by Snowflake Cortex and deployed via Snowpark Container Services.
The Business Challenge
When companies pursue compliance certifications of frameworks like SOC 2, ISO 27001, or HIPAA, they face a fundamental translation problem. Every organization describes their security practices differently. One company's "data encryption policy" is another's "cryptographic protection standards."
Consider the scale: SOC 2 alone can have over 200 criteria. For a typical mid-sized company, that might mean 50-100 custom controls that demonstrate the criteria are being met. Multiply this across many frameworks, and it can reach thousands of potential mappings that compliance teams must pair up manually.
Our Solution: Native AI on Snowflake
We built our control mapping system entirely on Snowflake's platform, leveraging two key technologies:
Snowflake Cortex: Provides native AI functions for embeddings and completions directly in SQL
Snowpark Container Services: Enables us to deploy our Streamlit web application alongside our data
For this use case, we leaned into Snowflake because the underlying customer data already lives there, and keeping everything on one platform eliminated multiple pain points: no API rate limits to manage, no network latency between services, no duplicate security layers.
The result? Our ML infrastructure complexity dropped to near zero. Updating embeddings became as simple as adding a dbt model with Cortex functions. The application runs internally, where our customer success team uses it daily to map custom controls to framework criteria - processing what used to take hours in just minutes.

The Technical Architecture
Hybrid Semantic and Keyword Matching
Retrieval for data within niche business contexts is prone to misalignment. Pure semantic search captures concepts but can miss critical technical terms, while pure keyword matching can be too rigid for natural language variations. Our solution combines both approaches using Snowflake Cortex.
For semantic search, we use Snowflake's AI_EMBED function to generate semantic embeddings, and similarity scores:

For keyword matching, one of our key innovations was implementing the complete TF-IDF algorithm in Snowflake SQL, enabling us to process millions of documents without external dependencies. This approach lets us calculate document similarity scores for thousands of controls in parallel, leveraging Snowflake's distributed compute.
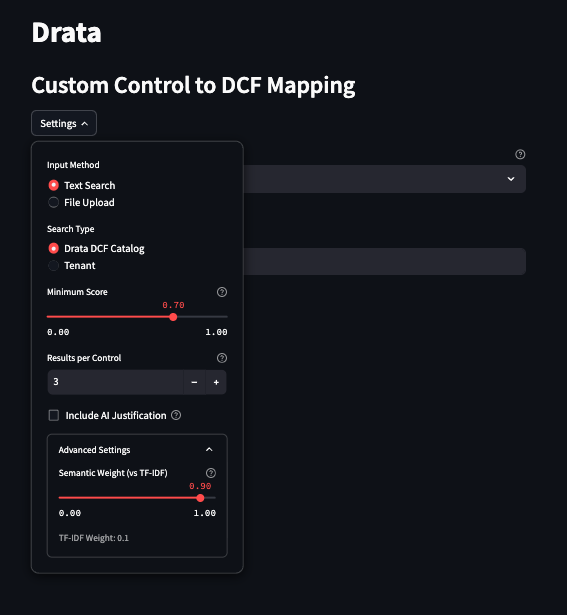
AI-Powered Explanations with Cortex
Beyond just finding matches, we use Snowflake Cortex's AI_COMPLETE function to generate human-readable explanations using state-of-the-art LLMs:
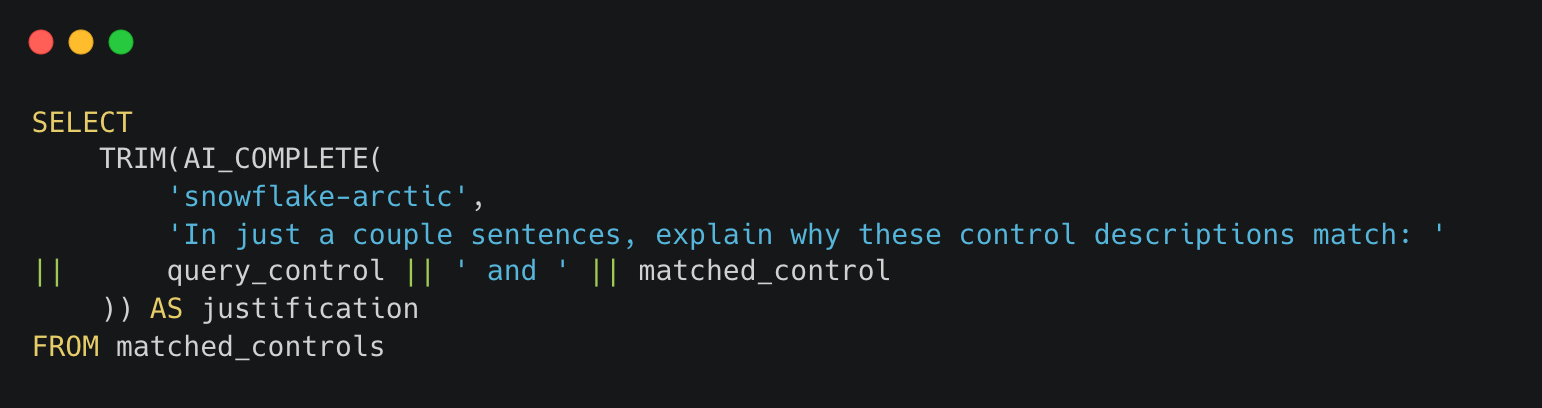
These explanations are crucial for building trust with compliance teams who need to understand and validate automated recommendations.
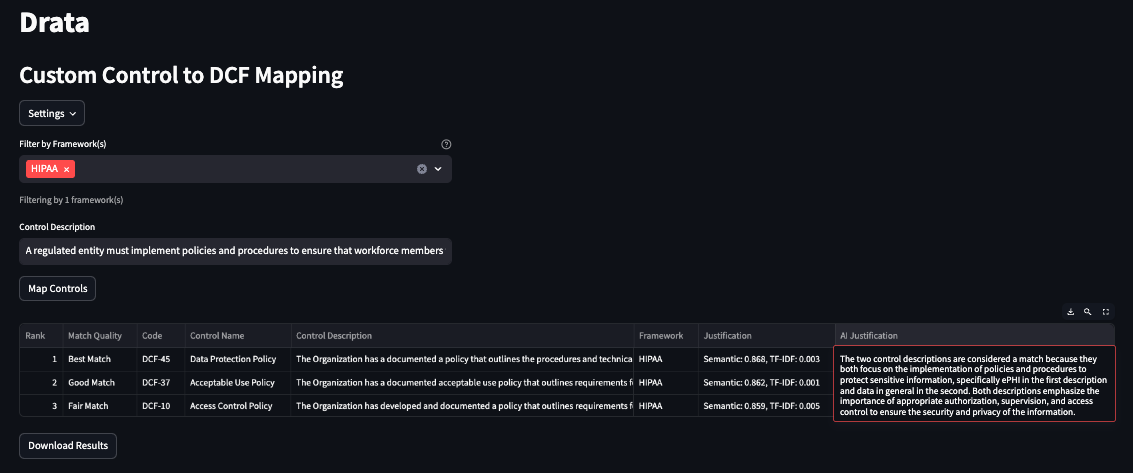
Deployment via Snowpark Container Services
Bringing it altogether, the infrastructure that makes all this possible is Snowpark Container Services (SPCS). SPCS gives us:
Zero Network Latency - Our Streamlit application runs directly alongside our data and AI models in Snowflake. There's no network hop between the UI, the data, and the AI processing.
Unified Security Model - Authentication, authorization, and data access all flow through Snowflake's security layer, handled by OAuth.
Automatic Scaling - Snowflake handles all compute scaling while providing limits on compute pooling and instance concurrency. When usage spikes during audit season, the platform automatically provisions additional resources within the ranges specified.

Simplified Operations - No Kubernetes clusters to manage. No ML infrastructure to maintain. No separate deployment pipelines. Everything runs on Snowflake.
Real-World Performance
Speed
Single control: <5 seconds
Bulk processing: 500+ controls in <5 minutes
Concurrent users: No degradation (within specified resource limits)
Accuracy (from our continuous evaluation system)
Average first pass accuracy: 93%+
Efficiency
~70% reduction in execution time vs external AI services
No ML infrastructure overhead
Pay only for compute used
Continuous Quality Assurance Through Automated Evaluation
One critical challenge with production AI systems is maintaining consistent quality over time. We built a lightweight evaluation framework that runs automatically after every search session, validating our results without impacting user experience.
The Challenge
Traditional ML evaluation typically assumes a static problem space. Compliance control mapping is anything but static; frameworks update quarterly, organizations rewrite controls continuously, and new regulations emerge regularly. We needed evaluation that evolves with our data.
Dynamic Test Generation
Rather than maintaining fixed test cases, we generate them on-the-fly from current control data. After each search completes, our system:
Samples random controls from the active dataset
Creates diverse test cases:
Exact matches: Full control descriptions verbatim
Paraphrases: Simple word substitutions
Partial matches: Portions of descriptions
Keyword tests: Domain-specific terms
Executes in background via Python threading
Stores results in Snowflake for trend analysis
The evaluation reuses the same batch search functions users experience, ensuring we test the actual production code path.
Implementation
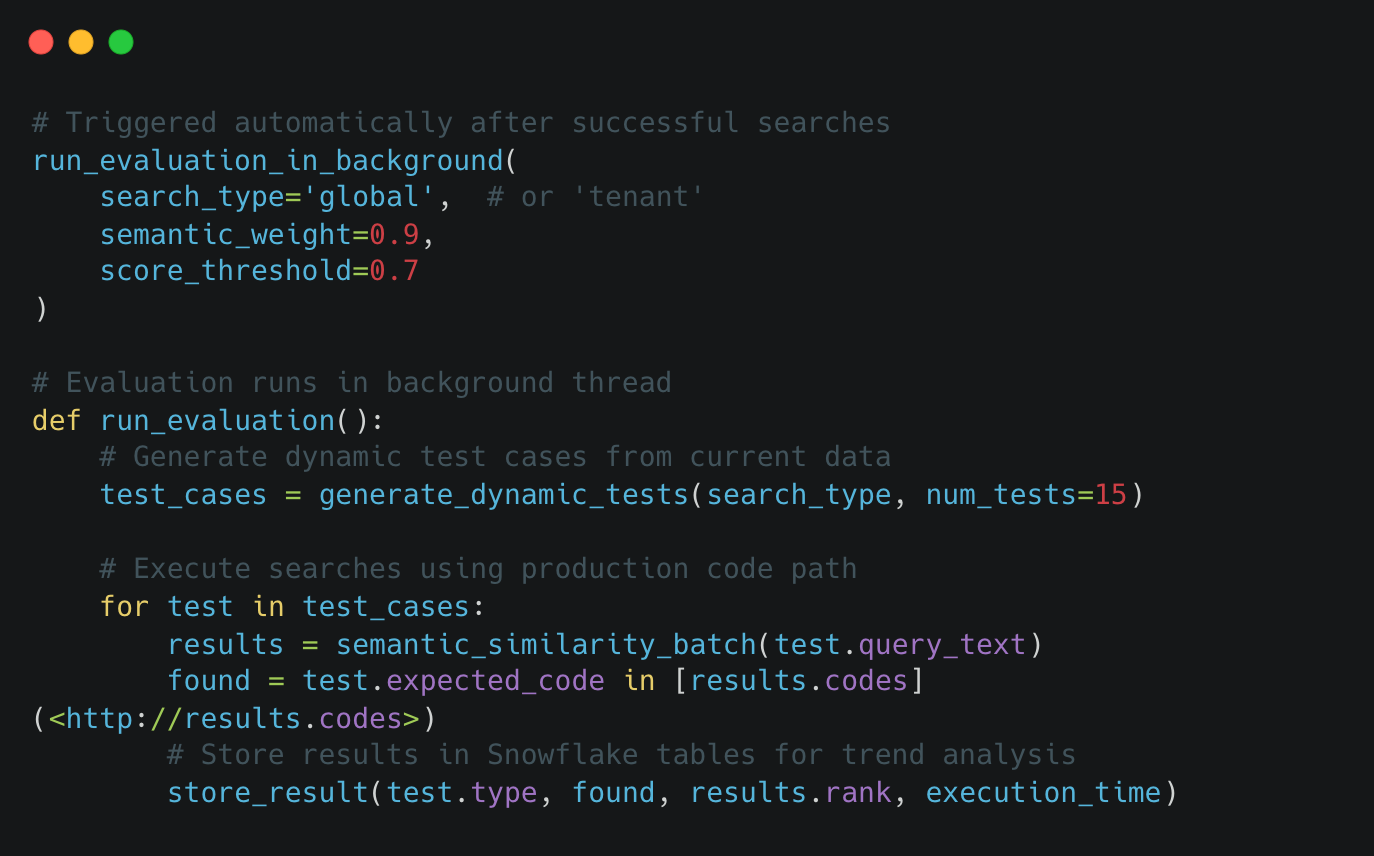
What We Track
For each test case, we measure:
Did we find the expected control? (pass/fail)
What rank was the first correct match?
How long did the search take?
Which configuration was used? (semantic weight, score threshold)
This enables us to answer critical questions:
Is overall accuracy declining?
Do paraphrases perform as well as exact matches?
How do configuration changes affect quality?
Real-World Performance
Our continuous evaluation system has been running in production since August:
Accuracy by Test Type:
Exact matches: 95.1% pass rate
Partial matches: 95.1% pass rate
Paraphrases: 92.9% pass rate
Overall System Metrics:
Average accuracy: 93.4% across all test types
Average rank when found: 1.01 (matches appear as the #1 result)
Key Benefits
Always Current - Tests automatically adapt as control data evolves
Zero Maintenance - No manual test case curation required
Production Fidelity - Tests use the exact same functions and data that users experience
Actionable Insights - Detailed metrics enable trend analysis and configuration optimization
Lessons Learned
Building a production AI system entirely on Snowflake taught us several key lessons:
1. Native Functions Eliminate Complexity
Using Cortex's AI_EMBED and AI_COMPLETE removed the need for separate embedding services, vector databases, and LLM APIs.
2. SQL Can Handle Complex Algorithms
We successfully implemented TF-IDF, batch processing, and evaluation systems entirely in SQL, leveraging Snowflake's computational power.
3. Container Services Changes Everything for Data Apps
Deploying our application directly on Snowflake via Container Services eliminated an entire layer of infrastructure complexity.
4. Hybrid Approaches generally Outperform Pure Methods
Our 90/10 semantic/keyword blend outperforms either approach alone for niche contexts.
What's Next
We're continuing to push the boundaries of what's possible with Snowflake's platform:
Enhanced Models: Testing new Cortex models as they become available
Reranker: Implement a proper reranker based on enhanced context
Multi-Language Support: Expanding beyond English for global customers
Predictive Capabilities: Using historical data to predict control gaps
Conclusion
By leveraging Snowflake Cortex and Container Services, we've built a sophisticated AI-powered data application that solves a real business problem at scale. The key innovation isn't any single algorithm or technique, it's the ability to deploy everything on a single platform with zero infrastructure overhead.
This approach has allowed our small team to build and maintain a system that would traditionally require a much larger engineering organization. We're processing millions of controls monthly, supporting hundreds of customers, and continuously improving, all without managing any ML infrastructure.